Overview of DIFO
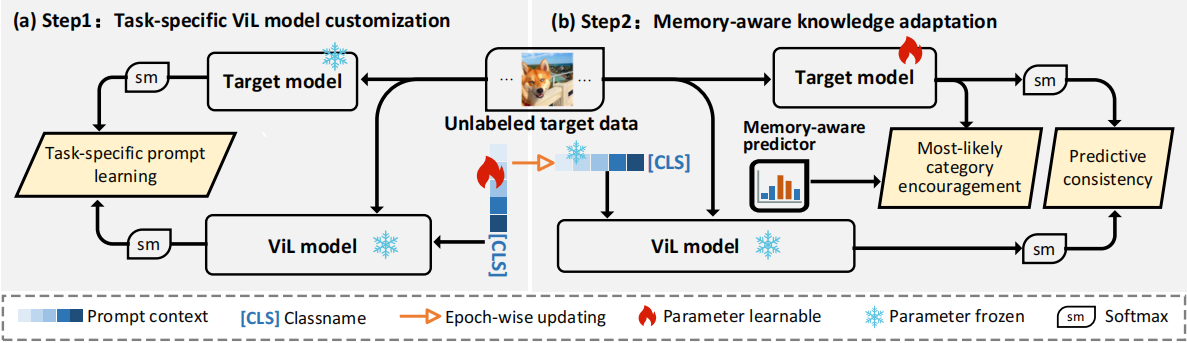
The process involves two alternating steps. First, we perform (a) task-specific customization of a ViL model through task-specific prompt learning (LTsc). This is achieved under soft predictive guidance using mutual information maximization. Second, we undertake (b) memory-aware knowledge adaptation, incorporating two regularizations: most-likely category encouragement (LMCE) predicted by our dynamic memory-aware predictor, along with the typical predictive consistency (LPC). These regularizations are designed to facilitate a coarse-to-fine adaptation.
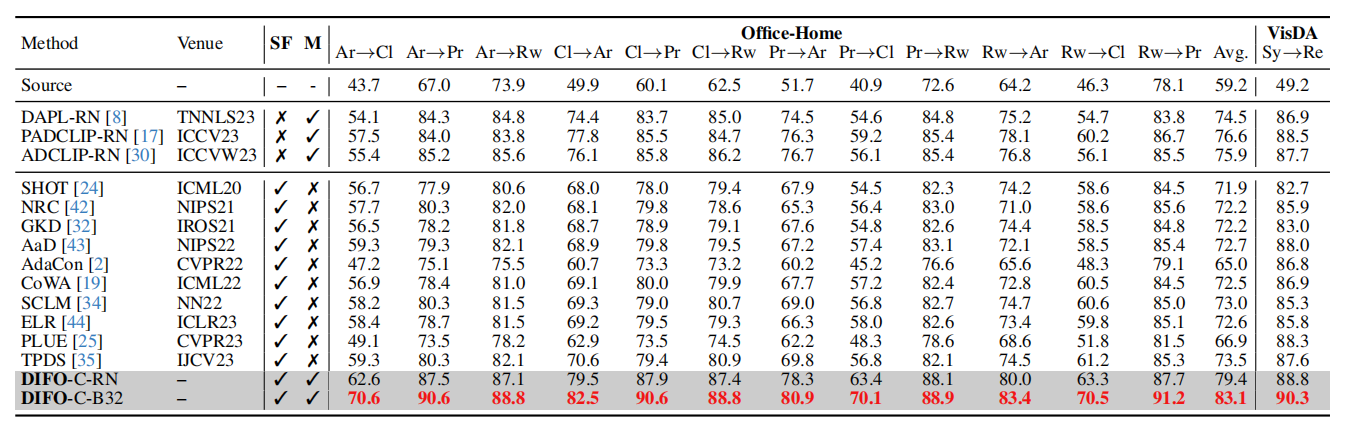
Result
Closed-set SFDA on Office-Home and VisDA (%). SF and M means source-free and multimodal, respectively; the full results on VisDA are in Supplementary.
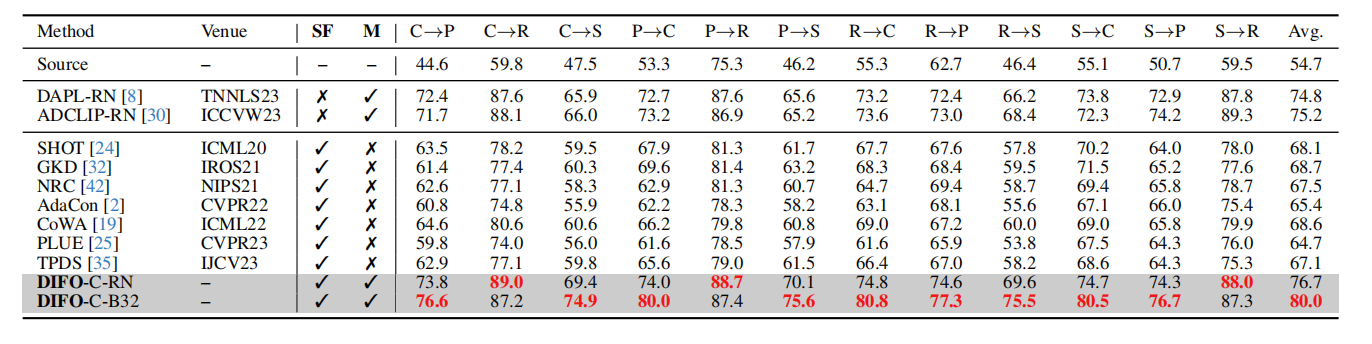
Closed-set SFDA on DomainNet-126 (%). SF and M means source-free and multimodal, respectively.
Results (%) of CLIP and Source+CLIP on the four evaluation datasets. The backbone of CLIP image-encoder in CLP-C-RN and CLP-C-B32 are the same as DIFO-C-RN and DIFO-C-B32, respectively. The full results are provided in Supplementary

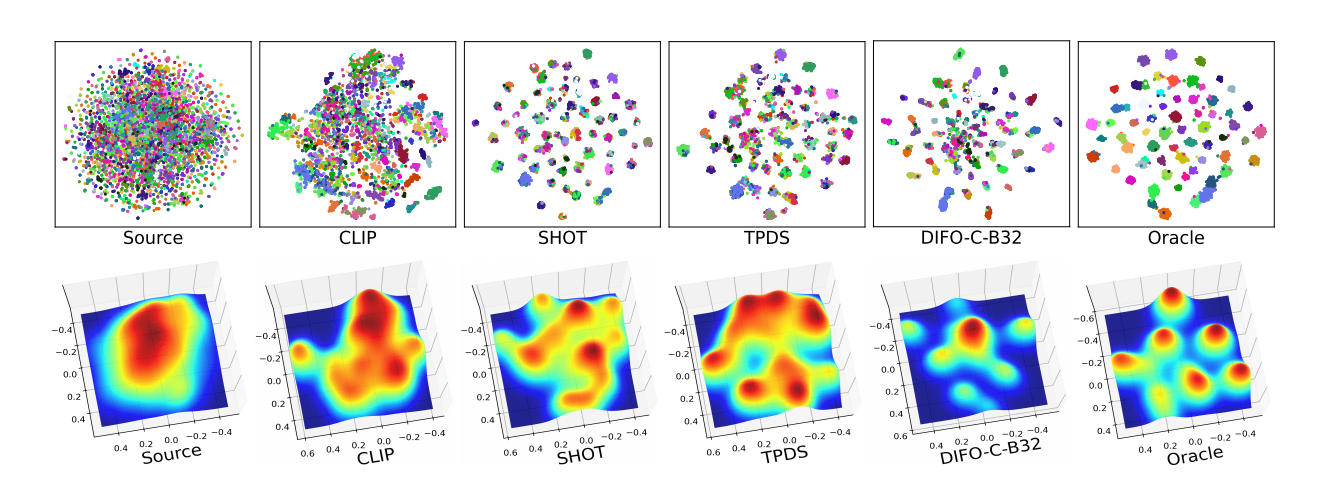
Feature distribution visualization comparison on transfer task Ar→Cl in Office-Home. Oracle is trained on target domain Cl using
the ground-truth labels. Different colors stand for different categories.